A Self-Supervised Reinforcement Learning Approach for Fine-Tuning Large Language Models Using Cross-Attention Signals
들어가며

2015년 개봉한 어벤저스 : 에이지 오브 울트론의 한 장면이다. 토니 스타크에 의해 만들어진 초지능 자비스와 그것을 뛰어 넘는 울트론이 만들어진 장면이다.
10년 전, 공상 과학 영화의 일부였던 자비스는 어느덧 chatGPT의 형태로, 혹은 수많은 LLM과 에이전트의 형태로 우리 곁에 성큼 다가왔다. 미용실에 전화를 걸어 커피를 예약하고, 고객센터에 전화를 걸어 나 대신 대기하게 할수도 있다. 아직 자동으로 아이언맨 슈트를 입혀주고 미사일을 발사하지는 않지만, 이제 드론이 러시아 공군 기지를 무인으로 초토화한다. (관련 자료) 영화 탑건 : 매버릭에서 미군이 순항미사일 수십발을 함정에서 발사해야 할 것을, 간단한 인공지능을 탑재한 드론이 트럭에서 날아올라 해냈다.
이 쯤 되니 일부 사람들은 울트론의 등장을 두려워하고 있다. 영화에서 묘사되는 것을 보면 울트론은 웹 상 여기저기를 욺겨다니며 자가 학습을 한 뒤에 인류 자체가 문제다 라는 결론에 이르렀다. 그 이후 온갖 빌런 행동을 저지르기 시작했고, 다행히 safety를 충분히 고려한 비젼이 성공적으로 울트론을 물리쳤다.
물론 gpt같은 거대 모델이 웹상을 돌아다니며 가중치를 욺겨다니기도 힘들고, agent의 행동 권한은 인간이 가지고 있기에 울트론이 실제로 탄생하기에는 아직 이르다. 그런데, 자가 학습 역시 현재의 LLM 훈련 방식과는 거리가 멀다.
크게 세 단계, pre-training, SFT, RLHF로 구성되는 단계에서 사람의 기여는 절대적이다. 특히 SFT와 RLHF에서는 수많은 instruction과 모범 답안들, 그리고 human annotator의 수고가 들어간다. 아직 LLM이 만들어지는 과정은 자가 학습과는 거리가 멀고, 영화에서처럼 천재 과학자 두 명이 뚝딱 만들어내지 않았다. 거대한 gpu 클러스터와 나이지리아 annotator들의 노동으로 이뤄낸 결과이다.
일부 AI 연구자들은 이제 자가 학습에 주목하기 시작했다. Absolute Zero라는 논문에서도 스스로 문제를 내고, 그 문제를 풀이하며 발전하는 LLM 훈련 프레임워크를 제안했다.
서론이 길었다. 이 논문 또한 자가 학습을 시도했다. 아직 부족하지만, LLM의 자가 학습의 방법 중 하나를 제시하는 본 논문을 리뷰해보겠다.
요약
본문에 들어가기 전에, 이 논문의 방법론은 아직 울트론식 자가 학습과는 거리가 멀다고 생각한다. 또한, 자가 학습이라는 공상 과학적인 용어보다는, 엄밀하게 말해 Self-Supervised Reinforcement Learning이다. 현재의 pre-training 기법도 Self-Supervised 방식의 masked token prediction인 것을 기억하면, 필자가 서론에서 울트론을 언급하며 온갖 어그로를 끌었던 것에 비해 실상 논문의 내용은 별 것 없다고 생각할 수도 있다. (ㅎㅎ)
어쨋든 이 논문은 Self-Supervised Reinforcement Learning이다. RL인 만큼 RLHF를 대체한다. 그러면 Human Feedback이 아니라 다른 무엇인가로 reward를 대체해야 한다. 그래서 이 논문에서는 Cross-Attention Signal을 사용한다. 여러분이 트랜스포머 구조를 대략 알고 있다면 알고 있는 그 Cross-Attention이 맞다. 각 토큰들간에 얼마나 서로 주목하고 있는지를 알 수 있는 정보이다. 이 Cross-Attention 값들을 가져와서 '프롬프트를 얼마나 잘 따르는가', '얼마나 프롬프트에 집중하는가', 그리고 '반복적인 말을 하지 않는가'에 대한 리워드를 계산한다. 이 리워드를 사용해 RL을 하면 주어진 프롬프트에 잘 따르고 반복적인 말을 최대한 하지 않는 LLM을 만들 수 있다.
실험 결과, 이 방법은 RLHF와 같은 human annotator를 통해 튜닝한 것의 성능에는 미치지 못했다. 그러나, 기본 모델이나 작은 리워드 모델을 사용한 것에 비해서는 더 높은 성능을 보여주었다.
리워드 구성
요약에서 언급한 것처럼 cross attnetion 값들을 직접 이용해 리워드를 구성한다.
먼저, 우리는 전체 layer들의 모든 attention 값들을 사용하지는 않을 것이다. 대체로 1개 혹은 3개의 마지막 레이어들의 attention 값을 활용한다. 선행 연구들에 따라 마지막 레이어에 의미있는 정보가 많이 담겨 있다는 이유이다. (특정 head만을 사용 가능하고, 모든 head를 사용할 수도 있다)
그래서, 각 output token을 생성할 때의 마지막 레이어의 프롬프트에 해당하는 토큰들의 attention 값들을 사용할 것이다.
이제 prompt coverage에 대한 리워드를 모델링하자. prompt coverage란 모델이 프롬프트의 명령에 얼마나 잘 따랐는지를 의미한다.
먼저 prompt 중에서 중요한 (핵심 정보를 담고 있는) 토큰을 정하고, 해당 토큰들의 attention 값들의 평균을 모든 generated token에 대해서 평균내준다. 그러면 이 값이 prompt coverage의 reward가 된다.
은 마지막 레이어고, 는 마지막부터 사용할 레이어의 개수이다. 은 레이어의 토큰과 토큰간의 attention 값이다. - 즉,
는 토큰과 토큰간의 attention 값을 각 레이어 별로 평균낸 것이다. 는 generated output(LLM의 대답)이고 는 프롬프트이다. 는 중요한 프롬프트의 토큰들이다. 즉, 중요한 프롬프트 토큰의 attention 값만을 prompt coverage에서는 사용한다.
다음으로는 LLM이 얼마나 집중하고 있는지를 리워드로 줄 것이다. 만약 어떠한 명령과 목적에 대해 잘 집중을 하고 있다면 attention pattern의 분포가 특정 토큰들에 매우 집중되어 있을 것이다. (다른 말로는 sharp할 것이다) (또 다른 말로는 엔트로피가 작을 것이다)
이를 알기 위해서 attention의 엔트로피를 측정한다. 엔트로피가 낮으면 더 sharp한 분포라는 것이고, 이는 모델이 어떠한 것에 더 집중하고 있다는 의미이다.
위와 같이 한 토큰에 대하여 모든 프롬프트 토큰들에 대한 attention 분포의 엔트로피를 구한다. 그리고 이 엔트로피를 generated output의 모든 토큰에 대해 평균을 내주면 된다. 마이너스 기호는 적은 엔트로피가 더 높은 리워드를 의미하도록 붙여준 것이다.
마지막으로 repeat penalty에 대한 리워드를 부여하는데, 이것을 cross attention을 사용하지는 않고 기존에 많이 사용되는 ngram과 같은 방식을 사용한다.
최종적으로는 이 세가지 (prompt coverage, focus, repeat penalty)를 더한 값을 prompt
훈련 과정
RL 학습에는 PPO를 사용하였다. 필자가 RL 관련 지식이 많이 부족한 관계로, 엄밀한 수식 등의 구현에 대해서는 본리뷰에서는 생략한다.
먼저, 기존 모델에서 한 쿼리에 대해 N개의 답변을 생성한다. 그 이후로, 마지막 몇 개의 레이어에서 N개의 답변에 대한 attention vector를 구한다. 해당 attention vector를 바탕으로 위에서 설명했던 리워드를 구하게 된다.
해당 리워드는 PPO를 통한 RL 훈련 과정에서의 리워드로 쓰인다. 여기서는 advantage를 현재 리워드에서 기존 policy의 (현재 프롬프트에 대한) value를 빼준 값으로 사용한다. 이 advantage를 최대화 하면서도, 기존 모델에 비해서 너무 다른 모델이 나오지 않도록 clipping을 통해 조절해준다.
이를 여러 에폭동안 반복하면서, 리워드를 최대화하는 모델로 튜닝된다.
실제 훈련 시 고려사항
- attention 값을 사용할 때, 어떤 레이어를 쓰고 어떤 attention head를 사용할 것인가.
- 주로 마지막 레이어를 사용한다
- 하지만 특정 태스크에서는 더 앞에 있는 레이어가 좋을 수도 있다. (프롬프트에 대한 전반적 이해를 담고 있을 수 있기 때문)
- 리소스 문제로 인한 확장성을 고려해야 한다. 실제로는 attention의 일부만 추출하던가, attention head의 일부만 추출하는 것으로 많은 메모리가 필요한 문제를 해결할 수 있을 것이다.
- 리워드 해킹을 방지하기 위해서, 엔트로피의 하한을 설정하는 등의 regularization 전략이 필요하다.
- 적은 human feedback과 함께 사용하는 hybrid approach는 더 높은 성능을 가져다 줄 수 있다.
- 아직 single-turn 환경에 대해서만 RL이 진행되었으며, multi-turn 및 reasoning까지 진화해야 한다.
실험 결과
- 사용 모델 : T5 및 BART (현대 LLM 튜닝 결과는 없음)
- 베이스라인 3종류
- RL을 적용하지 않음
- 작은 리워드 모델을 훈련하여 사용 (Synthetic Preference RL)
- RLHF (1,000개 정도의 레이블을 제공하여 상대적으로 작은 편)
- 생성한 QA 데이터셋과 5,000개의 instruction-response 페어로 실험함
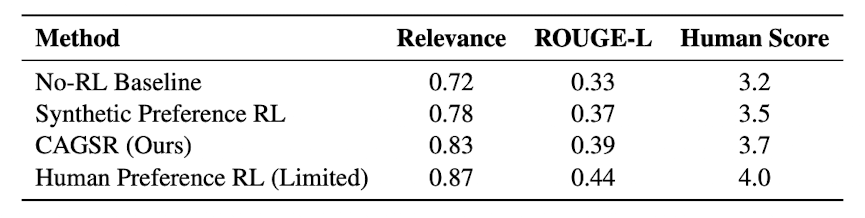
Human feedback보다는 점수가 낮았지만, RL을 하지 않거나 작은 리워드 모델을 사용한 것보다 높은 성능을 보여주었다.
결론
아직 이 논문의 한계점은 많다. single-turn에 대해서만 설계되었고, instruction을 따르는 능력이 늘어나는 정도의 효과를 가지도록 설계되었다. 우리가 울트론에게 기대하는 스스로 학습하며 엄청난 지능을 가진 인공지능을 만들 수 있는 방법은 확실히 아니다. reasoning 능력을 더 상승시키지도 않았으니 말이다.
그러나, 사람의 annotate에 덜 의존하면서 리워드를 주는 방식의 제안은 재미있었다. 현재 인공지능 발전을 위해서 데이터와 사람의 고품질 라벨링은 정말 필수적인데, 이것이 허락되지 않는 제약된 상황에서도 성능 향상을 시도해 볼 수 있다는 것에 의미가 있어 보인다.
또한, 이러한 자가 발전을 시도하는 연구가 쌓이다 보면 어느새 울트론을 만들 수 있는 능력이 인류에게 생기지 않을까 싶다. 울트론은 천재 과학자 2명이 아니라, 수많은 AI 연구자들의 삽질 끝에 만들어지지 않을까 싶다.